스프링의 데이터 액세스 철학

스프링 - 인터페이스 대상 객체 지향 코딩 지향 -> 서비스 객체가 바로 저장소로 접근하지 않음 -> 인터페이스를 통함
서비스 객체(Service object)는 저장소 인터페이스(Repository interface)를 통해서 저장소에 액세스한다. 특정 데이터 액세스 구현에 밀착되어 있지 않으므로, 쉽게 테스트 할 수 이다. 연결하지 않고도 테스트가 나가능하며, 데이터에 의한 테스트 실패도 발생하지 않는다.
데이터 액세스 계층은 퍼시스턴스기술에 상관 없이 액세스, 오직 관련 데이터 액세스 메소드만 인터페이스로 노출 -> 유연한 설계 가능
스프링의 데이터 액세스 예외 계층 구조
SQLException을 발생시키는 흔한 문제 -> 데이터베이스 연결 불가 / 쿼리 문법 오류 / 테이블, 컬럼 미존재 / 데이터베이스 제약사항 위배 등
-> 대부분 치명적인 문제를 일으키며, 문제를 제대로 인식하지 못한다. 근본적인 원인을 알기 위해서는 예외의 프로퍼티를 모두 살펴봐야함.
-> 따라서 퍼시스턴트 프레임워크에 따라, 예외에 간한 다양한 계층구조를 제공한다. (hibernate는 20개 이상의 예외 제공)
-> JDBC의 예외 계층 구조는 너무 포괄적이어서, 계층구조라고 할 것도 없음
-> 스프링JDBC에서는, 해당 문제를 해결하는 데이터 액세스 예외 계층을 제공한다. 일반 JDBC와는 대조적임
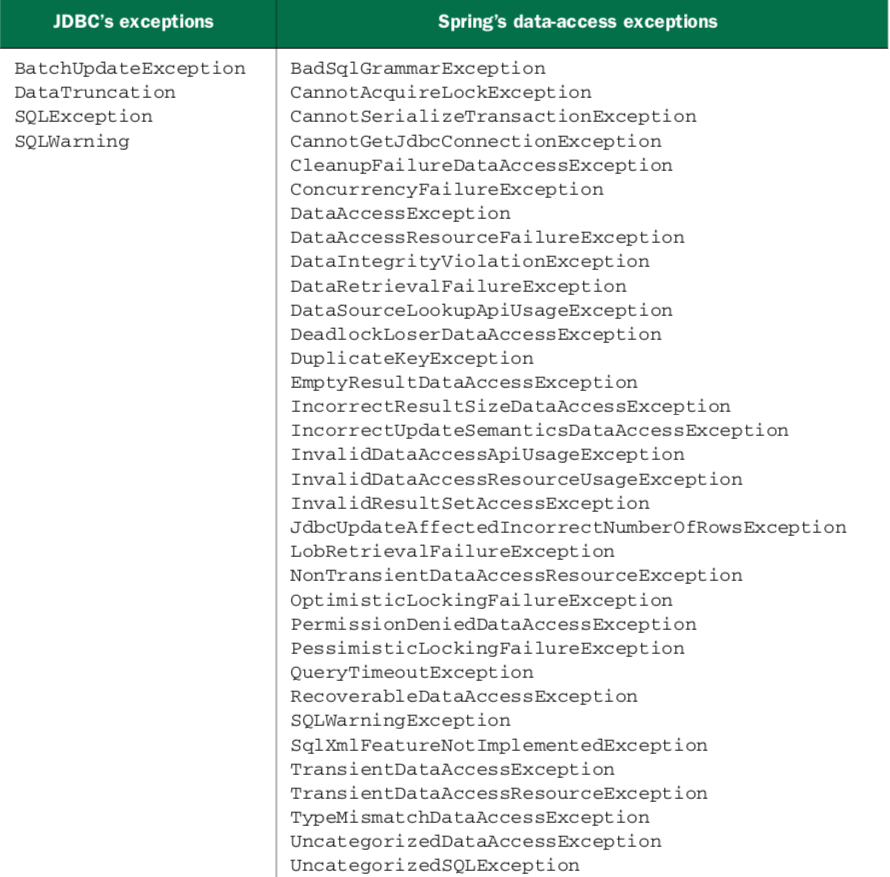
==> 스프링JDBC의 에외는 전부, DataAccessException을 확장한다. 특별한 점은 비검사형 예외이기 때문에, catch를 굳이 사용하지 않아도 된다(스프링의 많은 예외가 catch로 잡을 수 없기 때문으로 보임, 검사형의 경우 빈 catch블록도 강제됨)
데이터 액세스 템플릿화
템플릿 메소드 패턴
* 템플릿 메소드는 절차의 골격을 정의한다(고정적)
* 어떤 단계에서 프로세스가 그 단계의 작업을 서브클래스로 위임한다. 해당 서브클래스로 하여금 구현 종속적인 세부사항을 채우게 할 수 있음(가변적)
데이터 액세스 템플릿
* 데이터 액세스 절차에 있어, 디비 커넥션을 획득하고 반환하는 절차는 매번 반복된다 -> 절차의 골격(고정적)
* 하지만, 데이터 저장소와, 상황에 따라 작성해야할 각 데이터 엑세스 메소드는 서로 약간씩 다름 -> 가변적인 단계
-> 스프링은 이런, 절차에서, 고정단계 '템플릿template', 가변단계를 '콜백callback'이라는 두 가지 별도 클래스로 분리함

=> 스프링은 퍼시스턴스 플랫폼에 따라 선택가능한 템플릿을 제공 -> 대표적으로 JdbcTemplate, HibernateTemplate, JpaTemlate
데이터 소스 설정
스프링에 데이터 소스 빈을 설정하는 방법 - JDBC드라이버를 통해 선언, JNDI에 등록, 커넥션을 풀링
JNDI 데이터 소스 이용
대부분 JEE 애플리케이션 서버에 배포돌 것이다. 이런 서버는 JBoss, Tomcat과 같은 웹 컨테이너 역할을 함. 이 서버들은 모두 JNDI를 통해 데이터 소스를 획득하는 방법을 제공한다 - 외부에서 관리되며, 접근 시점에 요청만 하면 된다는 이점이 있음
JndiObjectFactoryBean 구현
@Bean
public JndiObjectFactoryBean dataSource() {
JndiObjectFactoryBean jndiObjectFB = new JndiObjectFactoryBean();
jndiObjectFB.setJndiName("jdbc/SpittrDS");
jndiObjectFB.setResourceRef(true);
jndiObjectFB.setProxyInterface(javax.sql.DataSource.class);
return jndiObjectFB;
}
풀링기능이 있는 데이터 소스 사용하기
JNDI로 데이터 소스를 가져올 수 없을 때, 차선책은 풀링 기능이 있는 데이터소스를 설정하는 것
* 아파치 공통 DBCP, c3p0, BoneCP 사용 가능
BasicDataSource 구현
@Bean
public BasicDataSource dataSource() {
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("org.h2.Driver");
ds.setUrl("jdbc:h2:tcp://localhost/~/spitter");
ds.setUsername("sa");
ds.setPassword(""); /// 여기까지 4개가 설정의 기본
ds.setInitialSize(5); // 풀이 시작 될 때, 커넥션 수
ds.setMaxActive(10); // 최대 커넥션 수
return ds;
}JDBC 드라이버 기반 데이터 소스
DriverManagerDataSource - 커넥션 요청할 때마다, 새로운 커넥션 반환, 풀링 되지 않음
SimpleDriverDataSource - OSGi 컨테이너 같은 특정 환경의, 로딩 문제를 극복에서 사용하는것 제외하면 DriverManagerDataSource와 동일하다
SingleConnnectionDataSource - 커넥션 요청시, 항상 동일한 커넥션 반환, 풀링은 기능은 없지만, 한 커넥션만을 풀링하는 데이터소스
-> BasicDatasource와 크게 다르지 않으나... 상용에서는 고려해야한다, 풀링기능이 없기 때문에 '멀티 스레드 어플리케이션'에서는 심각한 성능 저하를 야기한다.
-> 개발과, 테스트 이외 비추
구현 예시
@Bean
public DataSource dataSource() {
DriverManagerDataSource ds = new DriverManagerDataSource();
ds.setDriverClassName("org.h2.Driver");
ds.setUrl("jdbc:h2:tcp://localhost/~/spitter");
ds.setUsername("sa");
ds.setPassword("");
return ds;
}임베디드 데이터 소스
- 개발, 테스트에서 사용할 때, 괜찮은 선택 , 테스트를 할 때마다 테스트 데이터로 데이터베이스를 채울 수 있음
- 따로 네임 스페이스에 관한, 편의성 제공은 없음(xml 설정에는 존재).. EmbeddedDatabaseBuilder 사용
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.H2)
.addScript("classpath:schema.sql")
.addScript("classpath:test-data.sql")
.build();
}데이터 소스 선택을 위한 프로파일링
데이터베이스를 사용할 시, 환경별로 dev는 개발과 테스트에 용이한 임베디드 데이터소스, qa환경에서는 BasicDataSource, 그리고 상용환경에서는 jndiDataSource를 사용한다고 하자.
이런 경우에는 스프링의 프로파일을 이용하여 각각 dataSource를 지정할 수 있다.
구현 예시
@Configuration
public class DataSourceConfiguration {
@Profile("dev") // 개발 환경
@Bean
public DataSource embeddedDataSource() {
return new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.H2)
.addScript("classpath:schema.sql")
.addScript("classpath:test-data.sql")
.build();
}
@Profile("qa") // QA 환경
@Bean
public DataSource Data() {
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("org.h2.Driver");
ds.setUrl("jdbc:h2:tcp://localhost/~/qa");
ds.setUsername("sa");
ds.setPassword("");
ds.setInitialSize(5);
ds.setMaxActive(10);
return ds;
}
@Profile("prod") // 상용환경
@Bean
public DataSource dataSource() {
JndiObjectFactoryBean jndiObjectFactoryBean = new JndiObjectFactoryBean();
jndiObjectFactoryBean.setJndiName("jdbc/DS_PROD");
jndiObjectFactoryBean.setResourceRef(true);
jndiObjectFactoryBean.setProxyInterface(javax.sql.DataSource.class);
return (DataSource) jndiObjectFactoryBean.getObject();
}
}스프링과 JDBC
JDBC 장점 : 데이터 액세스 언어인 SQL을 바탕으로 만들어졌다. 퍼시스턴스 프레임워크를 사용했을 때보다 훨씬 낮은 수준에서 데이터 조작 가능, 개별 칼럼에 액세스도 가능하다. 특히 리포팅 부류에 편리함.
JDBC 단점 - 코드가 지저분하다(간단한 객체 하나에 20줄 이상 코드), SQLException 하나로 몽땅 처리하려는 욕심(예외 명확하지않고, catch도 두번이나 해야함), 20%의 코드만이 실제 쿼리 수행이고 80%는 단순 반복코드
====> 스프링은 이런 JDBC의 장점은 가져오고, 단점은 템플릿으로 보완한다.
JDBC 템플릿
단순 반복적인 데이터 액세스 코드를 템플릿 클래스뒤로 추상화해서 숨긴다.
* JdbcTemplate - 가장 기본적인 JDBC템플릿, 색인된 파라미터 기반의 쿼리를 통해 쉽게 데이터 액세스
* NamedParameterJdbcTemplate - SQL값들을 색인된 파라미터 대신, 명명된 파라미터로 바인딩하여 쿼리를 수행
* SimpleJdbcTemplate - 자바5가 제공하는 오토박싱, 제네릭스 등을 활용해 쉽게 템플릿 사용
JdbcTemplate을 사용하여 데이터 추가
JdbcTemplate은, DataSource가 있어야 동작
@Bean
pbulic JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}=> 이제, jdbcTemplate을 저장소로 와이어링도 할 수있고, 데이터베이스에 액세스도 가능
@Repository
public class JdbcCoffeeRepository implements CoffeeRepository {
private JdbcOperations jdbcOperations;
@Inject
public JdbcSpitterRepository(JdbcOperations jdbcOperations) {
this.jdbcOperations = jdbcOperations; // JdbcTemplate으로 구현된 인터페이스 정의 동작.. 느슨한 결합
}
~~~~~
}
///////////
@Bean
public CoffeeRepository coffeeRepository(JdbcTemplate jdbcTemplate) {
return new JdbcCoffeeRespository(jdbcTemplate);
}==> 단순화한 JdbcTemplate 기반의 INSERT 함수
private static final String SQL_INSERT_COFFEE = "insert into coffee (name, shot) values (?, ?)";
public void addCoffee(Coffee coffee) {
jdbcOperations.update(INSERT_COFFEE, coffee.getName, coffee.getShot);
}==> 단순화한 JdbcTemplate의 SELECT함수(rowMapper 람다 사용 / 참고 https://codeday.me/ko/qa/20190404/236877.html )
public static final String SQL_SELECT_COFFEE_BY_NAME = "select name, shot from coffee where name = ?";
public Coffee findOne(String name) {
return jdbcOperations.queryForObject(
SELECT_COFFEE_BY_NAME
, (rs, rowNum) -> {
return new Coffee(
rs.getString("name")
, rs.getInt("shot"));
}
, id);
}
명명된 파라미터 사용
개발을 하다가, 부득이하게 SQL의 순서가 바뀐다거나 하면, 목록에 맞게 코드도 바꿔주어야 한다. 파라미터가 명명되어 있다면 SQL의 순서가 바뀌어도 코드는 그대로 가져갈 수 있다
명명화된 파라미터 SQL문 예시
private static final String SQL_INSERT_COFFEE = "inster into coffee (name, shot) values (:name, :shot)";
// 기존 (?, ?)에서 (:name, :shot) 으로 변경* NamedParameterJdbcTemplate 사용
@Bean
pbulic NamedParameterJdbcTemplate jdbcTemplate(DataSource dataSource) {
return new NamedParameterJdbcTemplate(dataSource);
}=> 명명화된 파라미터 INSERT 예시
private static final String SQL_INSERT_COFFEE = "insert into coffee (name, shot) values (?, ?)";
public void addCoffee(Coffee coffee) {
Map<String, Object> paramMap = new HashMap<Sring, Object>;
paramMap.put("name", coffee.name);
paramMap.put("shot", coffee.shot);
jdbcOperations.update(INSERT_COFFEE, paramMap);
}
'책 읽기 > 스프링 책 읽기' 카테고리의 다른 글
| 스프링 책 읽기(Spring in action) - 12. NoSQL 데이터베이스 사용하기 (0) | 2019.12.02 |
|---|---|
| 스프링 책 읽기(Spring in action) - 11. ORM을 통한 데이터 퍼시스팅 (0) | 2019.12.02 |
| 스프링 책 읽기(Spring in action) - 9. 웹 애플리케이션 보안(스프링 시큐리티) (0) | 2019.11.22 |
| 스프링 책 읽기(Spring in action) - 7. 고급 스프링 MVC (0) | 2019.11.15 |
| 스프링 책 읽기(Spring in action) - 6. 웹 뷰 렌더링 (0) | 2019.11.12 |



